
Durante anos, as gigantes da Internet definiram a agenda global de pesquisa em IA. Agora, grupos como Black in AI e Queer in AI estão buscando mudar esse cenário. Conseguirão?
Por Cristina De Luca no THE SHIFT

O mercado global de IA está projetado para atingir US $ 998 bilhões em 2028, representando uma taxa composta de crescimento anual de 40,2%, de acordo com relatório recém publicado pela Grand View Research. Os dados mostram uma movimentação de aproximadamente US $ 60 bilhões em 2020, chegando aos US $ 100 bilhões este ano. Os analistas da Grand View observam que as organizações estão injetando IA em praticamente todos os seus programas esstratégicos, de carros autônomos a equipamentos médicos. E cita especificamente Amazon, Google, Apple, Facebook, IBM e Microsoft como investidores significativos em P&D para IA. Essas empresas transformaram a IA na parte central de seus negócios.
Ao mesmo tempo, as Big Techs se tornaram grandes investidoras também em pesquisas de IA baseadas nas universidades, influenciando fortemente suas prioridades científicas. Com o passar dos anos, cada vez mais cientistas ambiciosos passaram a trabalhar para gigantes da tecnologia em tempo integral ou adotaram uma dupla afiliação.
De 2018 a 2019, 58% dos artigos mais citados nas duas principais conferências de IA tiveram pelo menos um autor afiliado a um gigante da tecnologia, em comparação com apenas 11% uma década antes, de acordo com um estudo realizado por pesquisadores da Radical AI Network, um dos grupos que busca desafiar a dinâmica de poder em IA, segundo reportagem do MIT Technology Review. Os outros são o Black in AI e o Queer in AI.
O Black in AI se tornou o centro intelectual para expor a discriminação algorítmica, criticar a vigilância e desenvolver técnicas de IA eficientes em dados. O Queer in AI se tornou um centro para contestar as formas como os algoritmos violam a privacidade das pessoas e os classificam em categorias delimitadas por padrão.
Esses grupos afirmam que a agenda corporativa para IA se concentrou em técnicas com potencial comercial, ignorando em grande parte as pesquisas que poderiam ajudar a enfrentar desafios como desigualdade econômica e mudanças climáticas. Na verdade, tornou esses desafios piores. O impulso para automatizar tarefas custou empregos e levou ao aumento de trabalhos tediosos, como limpeza de dados e moderação de conteúdo.
Para eles, o aprendizado profundo também criou uma cultura na qual nossos dados são constantemente copiados, muitas vezes sem consentimento, para treinar produtos como sistemas de reconhecimento facial. E os algoritmos de recomendação exacerbaram a polarização política, enquanto grandes modelos de linguagem não conseguiram limpar a desinformação.
Por isso, pesquisadoras como Rediet Abebe, professora assistente de ciência da computação na Universidade da Califórnia, Berkeley, e Timnit Gebru, ex-co-líder da equipe ética de IA do Google, estão empenhadas em promover mudanças, como mudar o foco das conferências tradicionais de ciência da computação das técnicas avançadas – como a recém anunciada IA do Google capaz de vencer os engenheiros humanos ao projetar microchips – para mais trabalhos com foco nos impactos sociais da IA. Certamente contarão com o apoio de Fei-Fei Li, Co-Diretora da HAI, em Stanford, nomeada para a Força-Tarefa de Pesquisa de Inteligência Artificial Nacional do governo americano.
Não será uma tarefa simples. Até porque, a produção da BIG Techs na área está aceleradíssima. Mas todos os feitos grandiosos começam pelo primeiro passo.
O IBM Research, por exemplo, vem experimentando computação analógica há décadas e recentemente desenvolveu um chip usando a memória de mudança de fase (PCM) para codificar os pesos de uma rede neural em um dispositivo de memória. O foco contínuo da empresa nessa tecnologia é evidenciado pelos artigos de destaque na conferência VLSI deste mês. Um dos destaques é o ecossistema para desenvolvedores em computação de rede neural analógica com a ferramenta AI Hardware Composer.
O Facebook acaba de revelar um sistema de recomendação de 12 trilhões de parâmetros. O artigo aborda avanços nos modelos de recomendação de aprendizado profundo (DLRMs).
A Microsoft se prepara para construir trilhões de modelos de parâmetros de IA. Se você achou que o GPT-3 era grande, ainda não viu nada… Muitos dos aspectos complicados de aumentar a IA estão relacionados a descobrir quais operações de computação você deseja executar e onde executá-las. Ao treinar modelos de escala de parâmetros de bilhões ou trilhões, você precisa pensar em como maximizar a utilização de cada uma de suas GPUs, o que significa que você precisa dividir suas cargas de trabalho de treinamento entre os chips, de acordo com restrições como a largura de banda da rede , velocidades de processamento no chip, onde você armazenou os pesos de sua rede e assim por diante. O escalonamento parece uma ciência artesanal agora, com os profissionais descobrindo truques e princípios, mas somos processos pré-industriais para cargas de trabalho em grande escala.
Já o Google descobriu que dimensionar o número de parâmetros do modelo para ASR multilíngue em grande escala traz ganhos de desempenho significativos com um ganho concomitante na eficiência dos dados e custo de treinamento mais eficiente (medida em dias de TPU).
Dizem que a fonte da exponencialidade é a aprendizagem. E a IA, com todas as suas limitações, tem em seu cerne um ciclo de aprendizado integrado, impulsionado pelas Big Techs.
Vale lembrar que o Google enviou o maior número de artigos de IA entre as empresas de tecnologia na Conferência Internacional sobre Representações de Aprendizagem (ICLR) deste ano, de acordo com novas estatísticas do InfoQ.
A conferência, que aconteceu em maio, enfoca o ramo da IA conhecido como representação ou aprendizado profundo.
O Google e sua subsidiária DeepMind contribuíram com mais de 100 artigos, seguidos pela Microsoft com 53, IBM com 35, Facebook com 23, Salesforce com 7 e Amazon com 4.
Quatro dos artigos do Google / DeepMind ganharam o prêmio Outstanding Paper.
No geral, a conferência teve 3.014 inscrições, ante 2.604 em 2020. Houve 6.194 inscrições em comparação com 5.622 no ano passado.
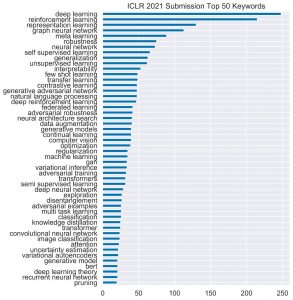
Em um tweet, o diretor do Laboratório de IA da Stanford University , Christopher Manning, exibiu as palavras-chave mais populares colhidas nos jornais, observando um aumento nas menções ao aprendizado por reforço.
FONTE: https://theshift.info/hot/para-essa-galera-e-hora-de-recuperar-a-ia-do-controle-das-big-techs/